


C’est la publication de l’ordonnance du 16 septembre 2021 qui donne naissance au registre national des sociétés afin de simplifier les démarches juridiques des entreprises et faciliter le travail de l’administration publique. Cette ordonnance missionne aussi l’INPI comme responsable de la création du RNE, de son suivi et de la mise à dispositions des informations […]
Données CRM fiables : pourquoi c'est la décision la plus rentable de l'année ?
Publié le 23/06/2026
0
Introduction
L’IA ne sera jamais meilleure que les données sur lesquelles elle travaille. Le problème, c’est que dans la plupart des PME, ces données sont moins fiables qu’on ne le croit.

Beaucoup d’entreprises activent aujourd’hui des outils d’intelligence artificielle avec de vraies ambitions : automatiser la prospection, enrichir les fiches clients, accélérer les devis, détecter les opportunités. Elles ont raison car l’enjeux est vital.
Pourtant beaucoup d’entre elles obtiennent des résultats décevants. Pas parce que l’IA est mauvaise. Mais parce que les données sur lesquelles elle s’appuie sont incomplètes, en double, obsolètes ou mal structurées.
Ce n’est pas un problème technique. C’est un problème de prérequis non validé.
La qualité des données CRM n’est plus un sujet réservé aux responsables informatiques, c’est une décision stratégique qui appartient au dirigeant.
Dans cet article, nous allons aborder simplement et sans parti pris : ce que coûte vraiment une base CRM dégradée, les quatre leviers pour y remédier, des exemples concrets d’entreprises françaises qui l’ont fait, et ce que cela a changé pour elles.
Ce que des données CRM de mauvaise qualité coûtent vraiment à une PME
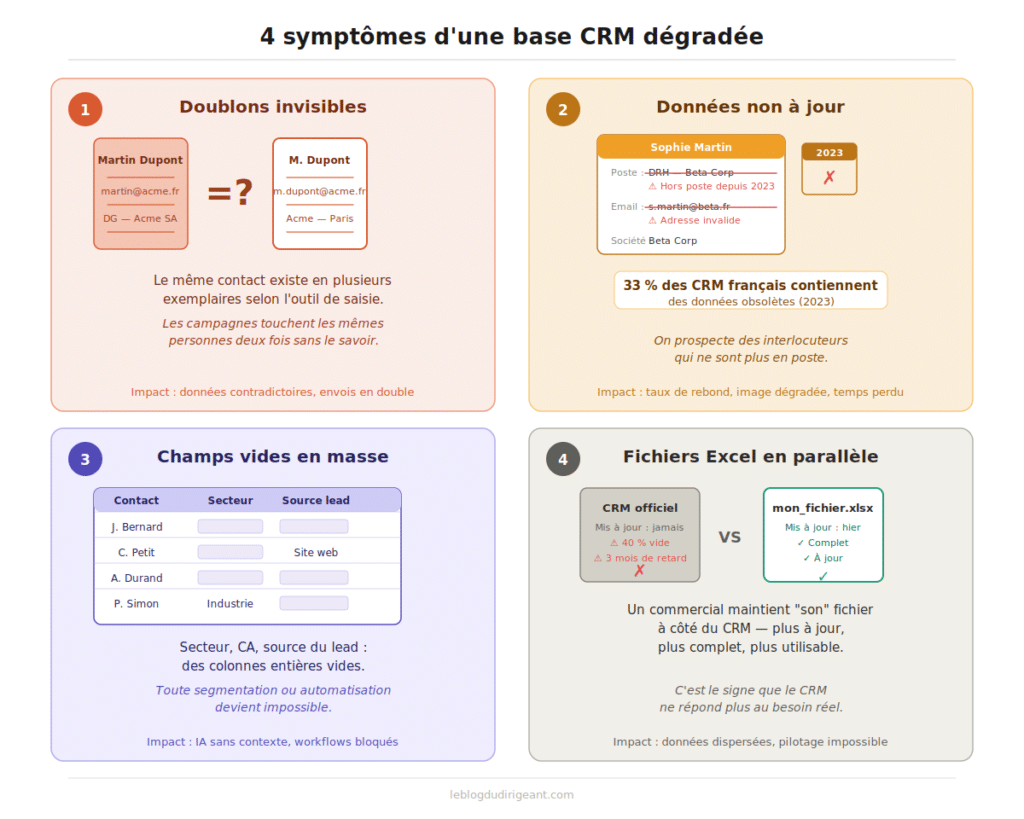
Les 4 symptômes d’une base CRM dégradée
Avant de parler solution, posons le diagnostic. Ces quatre signaux apparaissent dans presque toutes les PME, souvent sans que personne ne les nomme vraiment, parce qu’on finit par les considérer comme normaux. Ils ne le sont pas.
Doublons invisibles
Le même contact ou la même entreprise existe en plusieurs exemplaires selon qui l’a créé et depuis quel outil. Les campagnes marketing touchent les mêmes personnes deux fois. Les commerciaux travaillent sur des fiches différentes sans le savoir.
Données non à jour
Des contacts ont changé de poste, d’entreprise ou de coordonnées, mais les données CRM ne sont pas à jour.
On prospecte des interlocuteurs qui ne sont plus en poste depuis un an.
Champs vides en masse
Les fiches sont créées à la hâte, sans les informations essentielles. Le secteur d’activité, le chiffre d’affaires, la source du lead : des colonnes entières vides, qui rendent toute segmentation ou automatisation impossible.
Fichiers Excel en parallèle
Quelque part dans l’entreprise, un commercial maintient “son” fichier à côté du CRM. Il y est plus à jour, plus complet, plus utilisable. C’est le signe que le CRM ne répond plus au besoin réel.
Ces symptômes ne disparaissent pas seuls. Ils s’aggravent avec chaque nouvel utilisateur, chaque nouvelle intégration et chaque nouvelle entité qui alimente le CRM sans règle partagée.
Ce que ça coûte réellement : temps, décisions et IA
Le coût et les conséquences d’une donnée fausse est peu visible car elle ne génère pas de facture à payer. Cependant, elle génère des décisions prises sur une base fragile, des opportunités manquées par manque de visibilité, et des projets IA qui déçoivent, non pas parce que l’IA est mauvaise, mais parce qu’on lui a fourni un mauvais contexte.
Les chiffres disponibles donnent une idée de l’ampleur du problème.
Pourtant, le coût le plus sous-estimé en 2026 n’est pas opérationnel, il est stratégique et concerne l’IA. Un modèle d’intelligence artificielle entraîné ou alimenté par des données de mauvaise qualité ne produit pas de mauvais résultats de façon aléatoire, il produit des résultats systématiquement biaisés, avec une apparence de confiance qui les rend encore plus dangereux.
Exemple d’Esri, une société française
Éditeur de logiciels SIG, Esri France a restructuré son modèle de données CRM avant de déployer des automatisations. Résultat : baisse de 50 % du temps passé sur les e-mails et de 70 % des imports/exports manuels. Le gain n’est pas venu d’un nouvel outil, il est venu de la structuration de ce qui existait déjà.
À retenir
Les symptômes sont visibles. Les coûts sont mesurables. Et les solutions existent, sans nécessairement tout reconstruire. La première étape n’est pas d’acheter un nouvel outil, c’est de comprendre quels leviers actionner dans quel ordre.
Les 4 leviers pour fiabiliser ses données CRM et ce que propose HubSpot Data Hub
Il n’existe pas une seule façon de fiabiliser une base CRM mais 4, qui correspondent à quatre niveaux de maturité différents. Pour être efficace, on ne commence pas par l’aspect le plus sophistiqué, mais par celui qui résout le problème le plus coûteux. Et on avance en respectant l’ordre proposé.
1- La synchronisation : en finir avec les outils en silo
La donnée qui vit dans plusieurs outils sans se synchroniser est une donnée qui ment. Elle est exacte dans un outil, obsolète dans un autre, absente dans un troisième. Chaque commercial travaille avec sa propre version de la réalité et personne ne le sait.
La synchronisation bidirectionnelle résout ce problème en connectant le CRM à tous les outils qui produisent ou consomment de la donnée : outil de facturation, plateforme e-mail, logiciel de support, outil RH, ERP. Quand une information est modifiée dans l’un, elle se met à jour dans tous les autres.
Ce que propose HubSpot Data Hub : Data Sync
Point de vigilance
Les logiciels de comptabilité français (Sage, Cegid, EBP) ne disposent pas toujours d’un connecteur natif HubSpot. Un connecteur tiers ou un développement spécifique est souvent nécessaire, à anticiper dans le budget.
2- La qualité automatisée : pour corriger sans s’épuiser
Nettoyer sa base manuellement une fois par trimestre, c’est perdre la bataille avant de l’avoir commencée. Les doublons reviennent, les champs se vident à nouveau, les formats divergent. La seule façon de tenir une base propre sur la durée, c’est d’automatiser la détection et la correction des problèmes au fil de l’eau.
Un outil de qualité automatisé surveille en permanence la base : il détecte les doublons, signale les formats incorrects, alerte sur les champs obligatoires manquants et propose des corrections. Sans intervention manuelle systématique.
Ce que propose HubSpot Data Hub : Data Quality Automation
Point de vigilance
La qualité automatisée n’est pas un confort, c’est un prérequis pour que les automatisations et l’IA fonctionnent correctement.
3- Le modèle de données : structurer avant d’automatiser
Un CRM propre sur un mauvais modèle, c’est un appartement bien rangé dont les pièces sont mal conçues. On peut nettoyer indéfiniment, si la structure de base est mauvaise, la donnée reviendra toujours au désordre.
Le modèle de données, c’est la décision qui précède toutes les autres : comment les entités sont définies, comment elles se relient entre elles, quelles propriétés sont obligatoires.
Ce que propose HubSpot Data Hub : Data Model Builder
Piège fréquent :
La plupart des PME créent 200 propriétés dans leur CRM alors que 40 bien définies suffiraient. Chaque propriété superflue est un champ que personne ne remplit, et qui dégrade mécaniquement le score de qualité de toute la base.
4- La consolidation des données : connecter sans être développeur
À mesure que l’entreprise grandit, ses données ne vivent plus seulement dans le CRM. Elles sont dans des entrepôts de données, des outils d’analyse, des bases externes. Le quatrième levier, c’est la capacité à consolider ces sources dans un espace unique, sans avoir besoin d’une équipe technique dédiée.
Ce que propose HubSpot Data Hub : Data Studio
Variable cachée à anticiper
Le Breeze Data Agent consomme 10 crédits par requête, avec 3 000 crédits par mois inclus en Pro. Pour une équipe qui l’utilise intensivement, cette limite peut être atteinte rapidement, et les crédits supplémentaires sont facturés en dehors de l’abonnement de base.
| Fonctionnalité | Gratuit | Starter | Pro | Entreprise |
| Synchronisation champs standards | ✓ | ✓ | ✓ | ✓ |
| Synchronisation champs personnalisés | ✗ | ✓ | ✓ | ✓ |
| Tableau de bord qualité des données | Basique | Basique | ✓ Complet | ✓ Complet |
| Automatisation qualité (doublons, formats) | ✗ | ✗ | ✓ 10M/mois | ✓ 25M/mois |
| Traçabilité des données | ✗ | ✗ | ✓ | ✓ |
| Objets personnalisés | ✗ | ✗ | ✗ | ✓ |
| Sandbox de test | ✗ | ✗ | ✗ | ✓ |
| Connexion entrepôts (Snowflake, BigQuery) | ✗ | ✗ | ✗ | ✓ |
| Breeze Data Agent (crédits IA) | ✗ | ✗ | ✓ 3 000 crédits/mois | ✓ Volume étendu |
Ce que ça change concrètement : 4 cas d’entreprises françaises
Les chiffres globaux donnent une idée de l’enjeu. Les cas concrets montrent ce qui se passe réellement quand une entreprise décide de prendre ses données CRM au sérieux, sans changer d’outil, sans recruter une équipe data, mais en restructurant ce qui existait déjà.
Lepermislibre et mc2i : quand la donnée multiplie les opportunités sans multiplier les équipes
Lepermislibre et mc2i sont 2 entreprises de taille et de secteur différents.
Elles font pourtant le même constat : une base CRM bien structurée génère plus d’opportunités sans augmenter les ressources. Le levier n’est pas l’outil, c’est la qualité de la donnée sur laquelle l’outil s’appuie.
Lepermislibre
Acteur français de la formation au permis de conduire en ligne, a restructuré son CRM pour centraliser et fiabiliser les données prospects et élèves.
Résultat : un ROI commercial multiplié par quatre et deux heures gagnées chaque jour sur le tri et le traitement des tickets, du temps qu’ils ont directement réinvesti dans la relation client.
mc2i
Cabinet de conseil en transformation numérique, a refondu son modèle de données pour aligner marketing et commercial sur une base commune. En douze mois : le nombre de leads a été multipié par 2,4, les rendez-vous commerciaux en hausse de 30 %, les transactions conclues en progression de 28 %.
Dans les deux cas, les résultats ne viennent pas d’un nouvel outil mais de la structuration et de la fiabilisation de la donnée existante. Le CRM était déjà là. C’est la qualité de ce qu’il contenait qui a changé.
Papernest et Esri France : quand la donnée devient un levier de chiffre d’affaires
Fiabiliser une base CRM ne génère pas seulement des gains de productivité. Dans certains cas, elle crée directement du chiffre d’affaires en rendant possible certaines tâches : le scoring, la priorisation, la personnalisation à grande échelle.
Papernest
Spécialiste de la gestion des contrats énergie et services pour les particuliers, a utilisé ses données CRM restructurées pour mettre en place un scoring commercial. En identifiant les contacts les plus susceptibles de convertir, l’équipe commerciale a pu concentrer ses efforts là où ils rapportent le plus.
L’entreprise explique avoir gagné un million d’euros de chiffre d’affaires et 100 % d’adoption de l’outil par les équipes. Dns un contexte commercial, c’est est souvent le signe le plus fiable d’un outil réellement utile.
Esri France
Editeur de logiciels de cartographie et d’analyse spatiale, a restructuré son modèle de données pour éliminer les processus manuels qui freinaient ses équipes.
Résultat : 50 % de temps en moins consacré à la gestion des e-mails, et 70 % de réduction des imports et exports manuels. Des heures récupérées chaque semaine sur des tâches qui n’auraient jamais dû exister si la donnée avait été correctement structurée dès le départ.
Poclain Hydraulics : la donnée comme colonne vertébrale d’une ETI industrielle
Dans l’industrie, la donnée CRM ne sert pas seulement à vendre, elle sert à anticiper. Les cycles commerciaux sont longs, les interlocuteurs multiples, les équipements suivis sur des années. Sans une base fiable, chaque information critique (date de renouvellement, historique d’intervention, statut du contrat, …) vit dans la tête d’un commercial ou dans un fichier que lui seul connaît.
Poclain Hydraulics est une ETI française spécialisée dans les transmissions hydrauliques. Elle a déployé un CRM avec un modèle de données structuré pour ses équipes commerciales mondiales.
Les résultats témoignent d’un changement d’usage profond :
- 90 % de connexion CRM dans les équipes, un taux exceptionnel dans un secteur industriel où l’adoption des outils reste traditionnellement faible
- 18 % d’offres commerciales supplémentaires saisies et tracées dans l’outil.
On voit ici que le taux d’adoption d’un CRM suit la qualité de la donnée qu’il contient, pas l’inverse. Si vos équipes n’utilisent pas le CRM, la première question à se poser n’est pas “comment les former” mais “est-ce que ce que le CRM contient leur est réellement utile ?”
Comment choisir ? Le guide pour les dirigeants
Il existe plusieurs façons d’améliorer la qualité des données CRM, et même s’il est souvent mentionné dans notre article du fait de son leadership, HubSpot n’est pas la seule réponse. La bonne solution dépend de votre organisation, de votre niveau de maturité data et de ce que vous gérez déjà. Voici un comparatif, suivi du coût qu’engendre l’utilisation d’HubSpot Data Hub.
Cinq solutions, cinq profils de PME
La question n’est pas quelle solution est la meilleure mais bien, laquelle correspond à votre situation.
| Solution | Point fort data quality | Limite principale | Profil PME adapté |
| HubSpot Data Hub | Qualité automatisée, Data Model visuel, synchronisation + 100 outils, IA intégrée | Fonctionnalités avancées réservées à Pro et Enterprise · Connecteurs ERP français parfois absents | PME sans équipe IT, qui veut une plateforme tout-en-un marketing + vente + data |
| Salesforce + Data Cloud | Vue client unifiée multi-sources, Einstein AI, Data Cloud puissant | Coût et complexité élevés · Nécessite souvent une équipe ou un intégrateur dédié | ETI et grandes PME avec équipe technique ou projet de transformation data avancé |
| Pipedrive | Simplicité, pipeline visuel, import propre | Outils de data quality natifs très limités · Pas de Data Model builder | Force de vente légère, TPE sans complexité data, priorité à la simplicité d’usage |
| Zoho CRM | Personnalisation étendue, Zia AI, déduplication native | Expérience utilisateur moins fluide · Intégrations moins larges | PME à budget serré qui veut personnaliser sans dépendre d’un éditeur unique |
| Microsoft Dynamics 365 | Intégration native Microsoft 365, Power BI, Dataverse | Complexité de déploiement · Coût de licence élevé sans partenaire | PME déjà dans l’écosystème Microsoft qui veut unifier CRM et outils bureautiques |
Combien coûte Data Hub ?
Le prix affiché est rarement le prix payé. Entre les niveaux d’offre, les frais d’onboarding obligatoires, les crédits IA et l’accompagnement d’un partenaire, la facture réelle peut surprendre un dirigeant qui s’est basé uniquement sur la grille tarifaire, sans prendre en compte l’intégralité des coûts engendrés.
Gratuit
- Synchronisation champs standards
- Tableau de bord qualité basique
- Visualisation Data Model
Starter : environ 20 €/mois
- Synchronisation champs personnalisés
- Idéal pour commencer la synchronisation inter-outils
Pro : environ 711 €/mois
- Qualité automatisée complète
- Data Lineage
- Google Sheets / Excel
- 3 000 crédits Breeze/mois
Entreprise : environ1 960 €/mois
- Objets personnalisés
- Sandbox
- Snowflake / BigQuery
- Reverse ETL
- Volume Breeze étendu
Par où commencer ? Les 4 premières actions d’un dirigeant
On ne repart pas de zéro. On commence par mesurer et on avance dans l’ordre du ROI décroissant.
| Auditer les doublons et les champs vides | C’est gratuit, immédiat, et c’est le seul moyen d’objectiver l’état réel de sa base. HubSpot propose un tableau de bord de qualité des données dès l’offre gratuite. Sans ce diagnostic, toute décision d’investissement repose sur des suppositions. |
| Synchroniser les 2 ou 3 outils principaux. | Identifier les outils qui produisent ou consomment de la donnée client en dehors du CRM (outil de facturation, plateforme e-mail, support, …) et les connecter. L’offre Starter suffit pour commencer. C’est le gain de productivité le plus rapide à obtenir. |
| Définir le modèle de données avant d’automatiser | Avant d’activer des workflows ou de lancer un projet IA, vérifier que le modèle de données est cohérent : quels objets existent, quelles propriétés sont réellement utilisées, quelles associations sont définies. Une heure passée à cette étape évite des semaines de correction plus tard. |
| Décider du niveau d’offre selon les fonctionnalités réellement nécessaires. | Lister les trois fonctionnalités qui résoudraient les trois problèmes les plus coûteux identifiés à l’étape 1. Vérifier à quel niveau d’offre elles sont disponibles. C’est ce niveau, et seulement celui-là, qui est justifié aujourd’hui. |
Ce qu’il faut retenir
FAQ sur la qualité des données d’un CRM
Qu’est-ce que la qualité des données CRM et pourquoi est-ce important ?
La qualité des données CRM désigne la fiabilité, la complétude et la cohérence des informations stockées dans un CRM (contacts, entreprises, transactions, historiques). Elle est essentielle parce qu’elle conditionne directement la performance des équipes commerciales, la pertinence des automatisations et la qualité des résultats produits par les outils d’intelligence artificielle. Une base dégradée ne génère pas d’erreur visible, mais des décisions prises sur des bases fragiles.
Combien coûte HubSpot Data Hub ?
L’offre gratuite donne accès à la synchronisation des champs standards et à un tableau de bord de qualité basique.
L’offre Starter démarre autour de 20 €/mois.
L’offre Pro, qui donne accès à la qualité automatisée complète, est facturée environ 700 €/mois.
L’offre Entreprise, qui inclut les objets personnalisés, le sandbox et les connexions aux entrepôts de données, est à environ 2.000€/mois.
À ces tarifs s’ajoutent des frais d’onboarding obligatoires (1 500 à 3 000 $) et les hausses tarifaires. Le coût total de la première année pour une PME B2B se situe généralement entre 15 000 et 40 000 €.
Quelle est la différence entre HubSpot Data Hub Pro et Entreprise ?
Quatre différences structurelles :
1- les objets personnalisés (Entreprise uniquement),
2- le sandbox de test (Enterprise uniquement),
3- la connexion aux entrepôts de données comme Snowflake ou BigQuery (Enterprise uniquement),
4- le volume de mises à jour automatiques (10 millions par mois en Pro contre 25 millions en Enterprise).
Si aucune de ces quatre fonctionnalités ne correspond à un besoin actuel, l’offre Pro est suffisante.
Comment nettoyer sa base de données CRM ?
En quatre étapes dans l’ordre :
1-auditer les doublons et les champs vides pour mesurer l’état réel de la base,
2-synchroniser les outils qui alimentent le CRM pour éviter que les silos recréent du désordre,
3-vérifier et corriger le modèle de données avant d’activer des automatisations,
4- maintenir la qualité avec des règles automatiques plutôt qu’avec des nettoyages manuels périodiques.
Un nettoyage ponctuel sans règles de qualité en continu ne tient pas dans la durée.
Pourquoi l’IA fonctionne mal quand les données CRM sont mauvaises ?
Un modèle d’intelligence artificielle produit des résultats à la hauteur du contexte qu’on lui fournit. Si ce contexte est incomplet, obsolète ou incohérent, l’IA ne génère pas des résultats aléatoires, elle génère des résultats systématiquement biaisés, avec une apparence de confiance qui les rend encore plus dangereux.
Sommaire
- Ce que des données CRM de mauvaise qualité coûtent vraiment à une PME
- Les 4 leviers pour fiabiliser ses données CRM et ce que propose HubSpot Data Hub
- Ce que ça change concrètement : 4 cas d'entreprises françaises
- Comment choisir ? Le guide pour les dirigeants
- Par où commencer ? Les 4 premières actions d'un dirigeant
- Ce qu'il faut retenir
- FAQ sur la qualité des données d'un CRM


Legalstart, partenaire du Blog du Dirigeant, répond à tous vos besoins juridiques

Simple

Économique

Rapide

Besoin d’aide pour créer votre entreprise ?
Besoin de changer d’adresse ?
Besoin de protéger votre marque ?


Articles pour aller plus loin
- Données sensibles dans votre CRM : risques, règles et bonnes pratiques
- Gestion multi-entités : comment structurer son CRM quand l'entreprise se développe ?
- HubSpot vs Salesforce : quel CRM choisir quand on veut structurer sa croissance sans se compliquer la vie ?
- HubSpot et la souveraineté des données : enjeux pour les PME européennes en 2025
- Le CRM est-il un gage d’efficacité commerciale ? (L’exemple HubSpot)
- Suivi des utilisateurs et automatisation : HubSpot à l’épreuve du terrain
- Guide complet : configurer HubSpot CRM en 10 étapes
- HubSpot CRM : un exemple concret de CRM bien pensé pour les TPE et PME
- Le CRM (HubSpot, Zoho, Pipedrive, Salesforce…) comme révélateur et moteur d’organisation interne
- Le CRM, miroir de l’organisation : ce que révèle l’usage d’HubSpot dans une PME
- La vérité sur le coût réel de HubSpot pour une PME
- De l’Excel au CRM : pourquoi les tableurs coûtent cher ? – Exemple HubSpot
- Installer un CRM, 70% d'échecs - Exemple HubSpot pour éviter les erreurs
- HubSpot pour un e-commerçant : CRM, intégrations et automatisations
- HubSpot et l’IA : une PME peut-elle en tirer parti ?
- HubSpot vs MailChimp : explications et comparaison des deux logiciels
- HubSpot CRM pour automatiser la prospection à froid
- HubSpot pour gérer une force de vente terrain
- HubSpot est-il adapté aux freelances et indépendants ?
- Meilleures intégrations HubSpot pour PME françaises (Qonto, Slack, Brevo, Zapier, etc.)
- HubSpot CRM est-il adapté à une stratégie multicanal ?
- HubSpot vs Odoo : quel CRM choisir pour votre entreprise ?
- HubSpot vs Zendesk : quel CRM choisir pour votre entreprise ?
- HubSpot vs Zoho : comparatif des outils marketing & CRM
- HubSpot est-il un CRM Retail : contours et explications
- HubSpot vs Monday.com : quel outil pour votre entreprise en 2025 ?
- HubSpot vs Pipedrive : quel CRM choisir ?
- HubSpot vs Brevo : comparaison détaillée et avis
- HubSpot CRM est-il adapté aux métiers de la beauté et du bien-être ?
- HubSpot est-il un outil de gestion tout-en-un de son entreprise ?
- Le CRM HubSpot est-il adapté pour les créateurs d’entreprise ?
- Test du CRM Hubspot Marketing automation
Plus d'articles
Articles qui peuvent vous intéresser

- creer
- une
- Dufour L.
- 20 Août 2025
- 7min

- gerer
- Lusset M.
- 25 Août 2025
- 5min
Comme leur nom l’indique, les conditions générales d’utilisation (CGU) ont but d’informer sur l’utilisation d’un site web, que ce dernier soit commerçant ou non. Les CGU peuvent être définies comme une sorte de contrat entre l’éditeur du site web, et la personne utilisatrice. L’utilité des CGU Les CGU rentrent dans la catégorie des contrats commerciaux. Les […]
- Petit G.
- 12 Nov 2025
- 12min
HubSpot séduit de plus en plus d’entreprises françaises parce qu’il centralise la relation client, du premier contact jusqu’à la fidélisation. Mais sa vraie valeur se révèle lorsqu’il est connecté aux autres outils utilisés par l’entreprise. Ces intégrations permettent de transformer un CRM en véritable cockpit de pilotage : tout est synchronisé, les tâches répétitives disparaissent, […]

- Dufour L.
- 14 Août 2024
- 4min
Le jeu vidéo s’impose aujourd’hui comme une nouvelle culture grand public, rassemblant de plus en plus de consommateurs via le casual gaming ou encore le free to play. Le jeu vidéo est devenu un média de masse et un pilier de la société connectée. Egalement à l’avant-garde des nouvelles technologies avec la réalité virtuelle et […]
Commentaires
0 commentaires
0/5
